ICE CREAM CS 175: Project in AI (in Minecraft) -- Minecraft Biome Landscape Image Completion
Status
Project Summary:
Given parts of images, our AI will predict and complete the image. Our AI will specialize in finishing images of minecraft biomes (such as landscapes of different biomes and buildings in those biomes). It will train on a database of images of this subject, learning how each complete image looks like. It will then be able to use this knowledge to finish constructing the remaining parts of images that it receives.
For example, if it receives the left half of an image, it will recreate the right half, and vice versa. Moreover, if it receives an image with the center missing, then it will fill in the center. The images will be filled in based on our AI’s understanding of how Minecraft biome landscapes generally look like (based on it’s training dataset).
Image completion/prediction is useful in augmented reality applications. For example, when placing a realistic augmented reflective item into the world, the item must reflect parts of the world it can not see. Image prediction can be used to estimate that part. Image prediction can also recreate faces of people when we only see a portion of their faces, this can be helpful for law enforcement. Image prediction can also help us recreate damaged photos with historical or sentimental importance.
Approach:
Data Collection
We decided to use the beach biome as our test biome, as the beach biome has many distinct features that we believed would be easy to spot (separation between ocean and sand, sand portion and ocean portion). To get images specifically of beach biomes, we manually went into Minecraft worlds, found beach biomes, and took screenshots. Although this dataset is very limited, we believe that it would be enough data to determine whether our GAN (see next section) was working or not.
We also wrote a Malmo script that has our agent run around in various Minecraft worlds collecting screenshots. The various Minecraft worlds were carefully chosen through online research (finding seeds of specific biomes that the agent could gather data in). For simplicity, we decided to keep the weather and time of day constant (clear weather and daytime) so that our agent could focus on the landscape of the biome.
We used Malmo to process these screenshots into the desired format. Since it is possible for the agent to get stuck in holes or caves, or take poor screenshots (angled into the ground or straight up into the sky, or taking pictures of landscapes or biomes we aren’t interested in), we need to look at the image folder and manually delete these unwanted images.
We then provide these images as training and test data for our GAN.
GAN
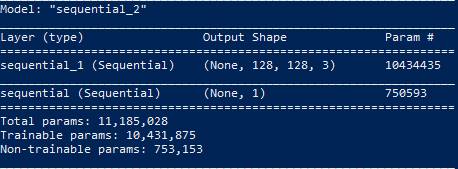
Our group’s approach was to use a generative adversarial network (GAN) to generate (and later) complete images. A GAN is made up of two neural networks, a generator, which generates fake images, and a discriminator, which classifies whether the images it receives are real or fake. The overall goal is to have the generator’s fake images fool the discriminator – meaning that the discriminator will think that the generated images are real.
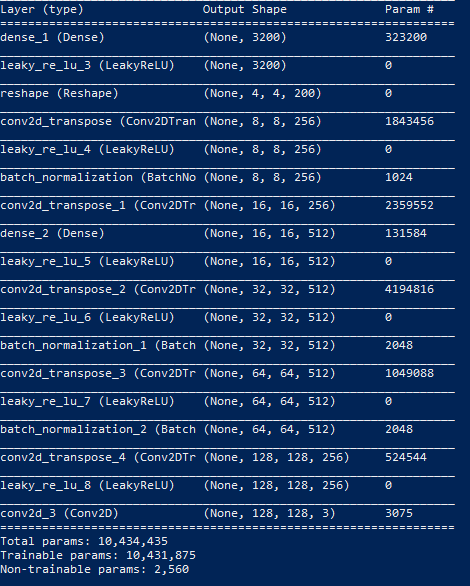
The generator model takes in a vector of points in latent space (essentially random points or noise). These points then flow through the generator’s neural network, becoming an image based on the generator’s previous learnings. Our generator model starts off with a dense layer of many nodes, allowing us to store multiple versions of the output image. We then reshape the image, allowing it to be used in the following layers. We used Conv2DTranspose layers to upsample our image (like the reverse of pooling). In particular, we used a stride of 2x2, which means that the image size doubles each time. Between each of the Conv2DTranspose layers, we use LeakyRelu (an activation function), which is used to transform an input signal to an output signal for the next layer. According to several websites, LeakyRelu is one of the best activation functions to use in image generation and classification (next section). We also used BatchNormalization, allowing us to standardize our inputs, giving us a more stable distribution. This is repeated until we have the image size that we want. The output layer is a Conv2D with 3 filters (3 channels (rgb) and a tanh activation to ensure that the output ranges are in the desired range of [-1,1], allowing us to easily output sample images).
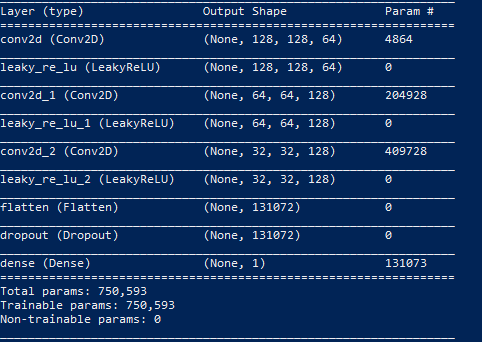
The discriminator model is trained to minimize binary cross entropy loss (as it is deciding whether the images are real or fake). It takes in a vector of input (image pixels), and uses Conv2D layers with a stride of 2x2 to downsize the input image (acting similar to pooling, reducing the amount of parameters and computation in the network). Between each of the Conv2D layers, it uses the same LeakyRelu function that was used in the generator. Our discriminator uses Dropout (randomly setting outgoing edges of hidden neurons to 0) to prevent overfitting. Lastly, it uses a fully connected Dense layer with a sigmoid activation to determine whether the image is real or fake.
The training of the GAN (ultimate goal is to have the generator produce images that fools the discriminator) is done in two steps. First, the discriminator trains on real images (taking directly from our dataset), and fake images (produced by the generator). The real images are labeled as real and the fake images are labeled as fake. Afterwards, the generator is trained through training the GAN model. The GAN model sends the generator’s output, and feeds it to the discriminator. During this step, these fake images are actually labeled as real images (when given to the discriminator). This means that if the discriminator cannot detect these mislabelled images, the loss will be small, indicating that the generator has done a good job at creating real looking fake images. After taking the discrimator’s feedback, the generator adjusts the weights in its network to optimize for successfully tricking the discriminator. We use the Adam version of stochastic gradient descent, as it is often listed across many websites and tutorials as one of the best optimizers for image generation. We have the GAN run over 50000 epochs, while having it output sample images every 500 epochs.
Our next steps would be to modify our GAN to take in partially completed images, so that it could complete those images instead of creating full fake images from scratch.
Discriminator Model:
GAN Model:
Generator Model:
Evaluation:
Quantitative results: In our proposal, our quantitative evaluation was to compare the pixel similarity between the whole image and the GAN completed image from the halved whole image. At this point, our GAN only generates new possible images and does not complete given images so we do not have a strict quantitative evaluation of our GAN. However, a loose quantitative improvement of our generated images can be seen from the outputs of discriminator and generator loss over each epoch. The discriminator loss shows how good the discriminator is at classifying fake and true images, while the generator loss shows how good the generator is at creating fake images. Our discrimnator’s loss value is very low meaning that it’s able to successfully distinguish between fake and real images. On the other hand, the generator’s loss remains high, suggesting that the images it is creating are not good enough to fool the discriminator. However, due to hardware constraints we are having trouble helping the generator make better fake images.
Qualitative results: Currently, we have our GAN output a sample of images every 500 epochs. This allows us to see sample images over time. We manually look at these images, and using our knowledge of Minecraft biome landscapes, we decide how realistic these images look. Depending on the results, we go and tweak our GAN, hoping to receive more realistic images.
Sample Latent Space Walk (Generative Model Output):
Sample Photos:

Output Results:
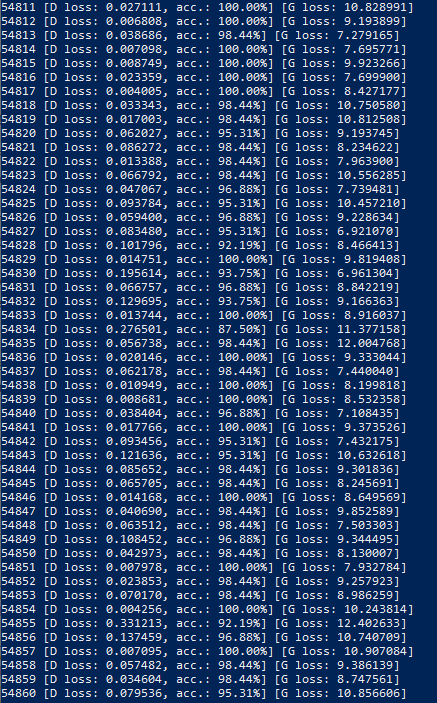
Remaining Goals and Challenges:
Our goal for the next four weeks is to have a finalized image completion software that is able to complete masked images using various masks upon different biomes. Another goal is to be able to scale up our image size.
Currently, we are facing hardware constraints, as the neural network to generate images larger than 128x128 pixels is unable to fit in our GPU’s memory. Moreover, we are limited in the amount of layers that we can add into our generator model, as this is also limited by the GPU’s memory space. If we can figure out a solution to speed up our training data and require less hardware usage, it will be a lot easier to generate higher quality images (more layers and bigger images).
We have an efficient method of gathering training data, and training different biomes should be more or less the same. The next step is to move on to phase two of training our GAN, which is to recognize masked images (instead of generating images from scratch). This would require our generator to generate realistic images to fool our discriminator and have the unmasked pixels of the input closely represent those pixels in the output.
Resources Used:
https://machinelearningmastery.com/upsampling-and-transpose-convolution-layers-for-generative-adversarial-networks/
https://machinelearningmastery.com/padding-and-stride-for-convolutional-neural-networks/
http://keras.io/api/preprocessing/image/
https://towardsdatascience.com/writing-your-first-generative-adversarial-network-with-keras-2d16fd8d4889
https://machinelearningmastery.com/how-to-develop-a-generative-adversarial-network-for-a-cifar-10-small-object-photographs-from-scratch/